使用AELFRED进行XML程序设计
-- 如何使用
AELFRED解析XML文件的基本过程为,首先要生成一个XmlParser的实例,并且为XmlParser提供一个XmlHandler,然后XmlParser读取一个XML文档,在XmlParser读取XML文档的过程中,如果XmlParser遇到不同的XML文档部分(元素,属性等等)时,XmlParser会调用XmlHandler中的相应方法。需要引起注意的是,同XERCES解析器不同,AELFRED不会把XML文档转换成一个树状的对象集合,而仅仅是线性地把XML文件读出来交给XmlHandler实现的代码来处理。下面一段代码展示了基本的程序构架。
在XmlHandler这个Interface中声明的方法如表1。当我们对文档进行处理时,我们需要实现这些方法来处理我们所遇到的个别的文档。
| 方法名 | 使用说明 |
| attribute(String name, String value, boolean specific) | 当XML文档中出现一个attribute时这个方法被调用。第一个参数是attribute的名字,第二参数是attribute的值,第三参数个表示是从xml文件中定义的还是从dtd中定义完成的。若如果为true则是从xml文档中定义,若为false则是dtd提供的缺省值。 |
| charData(char[] array, int offset, int length) | 当XML文档中出现字符串数据的时候这个方法被调用。第一个参数是包含字符串数据的字符数组,第二个参数是起始位置,第三个参数是长度。需要注意的是解析器可能把在一对tag内包含的字符串分成几个部分,连续调用charData方法若干次。 |
| doctypeDecl(String name, String publicID, String systemID) | 当遇到定义文件格式声明时这个方法被调用。第一个参数是文件类型名;第二个参数是public标识符,如果没有,那么为null;第三个参数为system标识符,如果没有,为null。 |
| endDocument() | 当XML文档结束的时候这个方法被调用,这个方法每处理一个XML文档仅仅会被调用一次。 |
| endElement(String name) | 当一个Element结束的时候这个方法被调用。参数为element的名字,即<>内的字符串。 |
| endExternalEntity(String systemID) | 外部文件结束时这个方法被调用。参数为外部文件的URI。 |
| error(String message, String systemID, int line, int column) | 当出现错误时aelfred调用这个方法。参数分别为错误信息,出错文件的URI,行,列。如果这个方法被调用了,那么aelfred可能不会停止解析过程,但是该文件肯定 |
| ignorableWhitespace(char[] data, int offset, int length) | 当出现可以被忽略的空格时这个方法被调用。第一个参数是包含空字符串数据的字符数组,第二个参数是起始位置,第三个参数是长度。 |
| processingInstruction(String target, String data) | 当在文档中遇到处理指令的时候,aelfred调用此方法。 |
| resolveEntity(String publicID, String systemID ) | 当处理外部文档时这个方法被调用。在这里可以校验不正确的URI,还可以转移到自己预定的文件上。 |
| startDocument() | 当文档开始时这个方法被调用,这个方法仅会被调用一次。 |
| startElement(String name) | 当一个Element开始时这个方法被调用。参数为element的名字。 |
| startExternalEntity(String systemID) | 当外部dtd文件开始时这个方法被调用。 |
对于不需要处理所有XML元素的情况下,我们可以通过继承HandlerBase类的方法来生成自己的处理器。下面一段代码展示了如何使用继承HandlerBase的方法进行XML工作。
用来解析的xml文件如下
相关的dtd文件如下
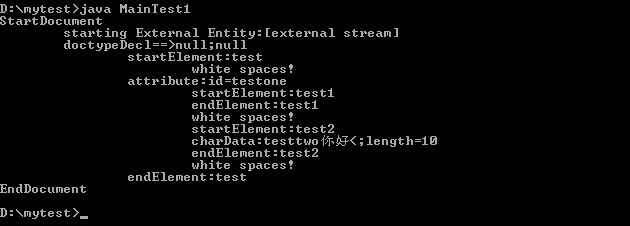
输出结果如下
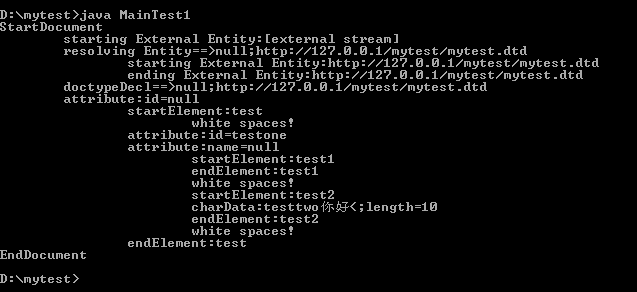
当xml文件使用外部dtd文件时,测试程序的输出结果如下
这个测试在windows 98,Apache1.3.9, Tomcat 3.2, jdk1.2, jdk1.3环境下运行通过。